Answer question No. 1 and any four from the rest.
1. Choose the correct answer: (10×1=10)
(i) Which of the following is a requirement of a Mutual Exclusion algorithm?
(a) Safety
(b) Liveness
(c) Fairness
(d) All of the above
(ii) Which event is concurrent with vector clock (2, 8, 4)?
(a) (3, 9, 5)
(b) (3, 8, 4)
(c) (1, 7, 3)
(d) (4, 8, 2)
(iii) If timestamps of two events are same, then the events are
(a) concurrent
(b) non-concurrent
(c) monotonic
(d) non-monotonic
(iv) Synchronizing the process clock time with UTC time is an example of
(a) Internal synchronization
(b) External synchronization
(c) Direct Synchronization
(d) None of the above
(v) The instantaneous difference in reading between two clock is known as
(a) Clock drift
(b) Clock skew
(c) Clock cycle
(d) None of the above
(vi) Java applet is an example of
(a) Mobile agent
(b) Mobile code
(c) Mobile node
(d) None of the above
(vii) The ability to hide that a resource can be moved from one location to another is known as
(a) Location Transparency
(b) Migration Transparency
(c) Relocation transparency
(d) Access Transparency
(viii) Which of the following is a variation of client server architecture?
(a) Proxy server
(b) Mobile code
(c) Mobile agent
(d) All of the above
(ix) If a process is executing in its critical section
(a) Any other process can also execute in its critical section
(b) No other process can also execute in its critical section
(c) One more process can also execute in its critical section
(d) None of the above
(x) For n processes, critical section invocation using Ricart Agrawala algorithm requires
(a) n-1 messages
(b) 2(n-1) messages
(c) n+1 messages
(d) None of the above
2. (a) Define distributed system? How it is different from computer network. (2+2=4)
Ans: A distributed system is one in which components located at networked computers communicate and coordinate their actions only by passing messages. We define a distributed system as one in which hardware or software components located at networked computers communicate and coordinate their actions only by passing messages. Distributed systems are widely used in various domains, including cloud computing, peer-to-peer networks, distributed databases, and large-scale web applications.
A distributed system is a collection of autonomous computers linked by a computer network and equipped with distributed system software. Distributed system software enables computers to coordinate their activities and to share resources of system like hardware, software and data also.
A distributed system is a network of interconnected computers that work together to achieve a common goal. In a distributed system, components are spread out across different locations and communicate with each other by passing messages over a network. These systems allow for parallel processing, fault tolerance, and scalability by distributing tasks across multiple nodes.
Difference between Distributed System and Computer network:
Distributed systems and computer networks are related concepts but have distinct differences. While computer networks provide the foundational infrastructure for devices to communicate and share resources, distributed systems build upon this infrastructure to enable collaboration and coordination among multiple nodes to achieve common goals or tasks.
Purpose and Functionality:
- Computer Network: A computer network is primarily focused on facilitating communication and data exchange between computers and other devices. It provides the infrastructure for devices to connect and transmit data, but it doesn’t necessarily imply that these devices are working together towards a common goal.
- Distributed System: A distributed system, on the other hand, involves multiple interconnected computers or nodes that collaborate to achieve a common task or goal. Unlike a computer network, a distributed system involves not only communication between nodes but also coordination and sharing of resources to perform tasks.
Scope of Communication:
- Computer Network: In a computer network, communication typically involves the exchange of data between individual devices or nodes. The network’s main function is to enable this communication, but it doesn’t necessarily dictate how the devices use this communication.
- Distributed System: Communication in a distributed system is more purposeful and often involves coordination and collaboration between nodes to achieve specific tasks. Nodes in a distributed system not only exchange data but also work together by sharing processing tasks, storage resources, and more.
Level of Abstraction:
- Computer Network: Computer networks are more concerned with the lower-level details of data transmission, such as protocols, routing, and physical connectivity.
- Distributed System: Distributed systems operate at a higher level of abstraction, focusing on the coordination and management of distributed resources to accomplish higher-level tasks or services. They abstract away many of the lower-level networking details and provide a more cohesive view of the system’s functionality.
Purpose:
- Computer Network: Computer networks are primarily designed to facilitate communication and resource sharing among devices.
- Distributed System: Distributed systems are designed to solve computational problems that are too large or complex for a single machine to handle efficiently. They aim to achieve goals such as scalability, fault tolerance, and parallel processing by leveraging multiple interconnected nodes.
(b) What is computer clock? Differentiate between hardware clock and software clock. (2+2=4)
Ans: A computer clock, often referred to as a system clock or internal clock, is a crucial component of a computer system responsible for keeping track of time. The computer clock generates regular electronic pulses, known as clock cycles or ticks, which synchronize the timing of all operations within the computer.
Computer clock is an internal timing device. It isa special hardware device on the motherboard that maintains the time. It is always powered, even when computer off. Computers use internal clock to synchronize all of their calculations. In order to synchronize all of a computer’s operations, a system clock- a small quartz crystal located on motherboard -is used. The internal clock in a computer is a crucial component that helps regulate and synchronize various activities within the system.
Difference between Hardware Clock and Software Clock:
There are 2 clocks in a computer. One is a hardware clock known as the Real Time Clock and the other is Software Clock. The software clock runs only when the computer is turned on. It stops when the computer is turned off. The hardware clock uses a battery and runs even while the computer is turned off. The hardware clock is a physical component of the computer system that provides persistent timekeeping even when the system is powered off, while the software clock is a component of the operating system that tracks time while the system is running. The software clock relies on the hardware clock for initialization and synchronization but operates independently once the system is booted.
The hardware clock, also known as the real-time clock (RTC), is a physical component of the computer’s motherboard or a separate integrated circuit. It is also known as RTC, CMOS or BIOS clock. It operates independently of the operating system and continues to run even when the computer is powered off. Hardware clock is a physical clock able to maintain the time while the system is powered off. This is the battery backed clock that keeps time even when the system is shut down. It runs independent of the state of the operating system all the time, also when the computer is shutdown. The battery driven hardware clock maintains the time while the computer is turned off. Its primary function is to maintain the current time and date even when the system is powered down. It is often used to set the system time during the boot process.
The Software Clock known as ‘system clock’ or ‘kernel clock’ that is maintained by the operating system (kernel) and whose initial value is based on the real-time clock. Once the system is booted and the system clock is initialized, the system clock is completely independent of the real-time clock. A software clock is maintained by the kernel while the system is powered on.
A key difference between a hardware clock (RTC) and the software clock is that RTCs run even when the system is in a low power state (including “off”), but the system clock (software clock) can’t. The software clock runs when the computer is turned on and stops when the computer is turned off. The hardware clock uses a battery and runs even while the computer is turned off. Unlike the hardware clock, the software clock is not persistent and does not operate when the system is powered off.
The hardware clock is reliable, we can rely on hardware clock to maintain an incrementing time while the system is powered off. The software clock is unreliable because it cannot. The software clock is accurate, we can rely on it to maintain the correct time. The hardware clock is inaccurate because it may lose time
(c) Define clock skew and clock drift. (2+2=4)
Ans: Clock skew and clock drift are two related concepts in timekeeping, especially in distributed systems. Clock skew refers to the immediate time difference between two clocks, while clock drift refers to the long-term divergence of a clock’s accuracy from a reference clock over time. Both are important considerations in designing and maintaining distributed systems where accurate timekeeping and synchronization are crucial.
Clock Skew:
- Clock skew refers to the difference in time between two clocks. The instantaneous difference between the readings of any two clocks is called their skew. The difference between two clocks at a given point in time is called clock skew.
- In distributed systems, where multiple computers or nodes communicate with each other, clock skew can occur due to factors such as network delays, differences in hardware clocks’ precision, and variations in temperature affecting clock oscillators.
- For example, if two nodes in a distributed system are supposed to execute a task simultaneously based on their local clocks, but one node’s clock is slightly ahead or behind the other, it results in clock skew.
- Clock skew can impact the correctness of distributed algorithms, synchronization protocols, and coordination between distributed components.
Clock Drift:
- Clock drift refers to the gradual divergence of a clock’s timekeeping accuracy from a reference clock over time.
- It arises due to factors like temperature variations, aging of components, and manufacturing imperfections.
- Clock drift causes a clock to run either faster or slower relative to a reference clock, resulting in timekeeping inaccuracies that accumulate over time.
- Techniques such as clock synchronization algorithms (e.g., NTP – Network Time Protocol) are employed to mitigate clock drift and maintain reasonable synchronization accuracy in distributed systems.
- In distributed systems, clock drift can increase clock skew issues, as nodes with higher clock drift may fall out of synchronization with other nodes more quickly.
(d) What is heterogeneity of a distributed system? (3)
Ans: Heterogeneity is one of the challenges of a distributed system that refers to differences in hardware, software, or network configurations among nodes. In distributed systems components can have variety and differences in networks, computer hardware, operating systems, programming languages and implementations by developers. Heterogeneity refers to the diversity or variety of hardware, software, and network technologies that are interconnected to form the distributed system.
Managing heterogeneity in distributed systems requires careful design, standardization, abstraction, and interoperability mechanisms to address the challenges posed by diverse hardware, software, network, data, and administrative environments. Techniques such as middleware, standard protocols, service-oriented architectures, virtualization, and containerization are often employed to mitigate the effects of heterogeneity and enable seamless integration and operation of distributed systems across diverse environments.
Middleware as software layers to provide a programming abstraction as well as masking the heterogeneity of the underlying networks, hardware, OS, and programming languages (e.g., CORBA). Heterogeneity refers to the ability of the system to operate on a variety of different hardware and software components.
3. (a) Define logical clock. How it is used to timestamp events? What are the shortcomings of logical clock. (2+2+2=6)
Ans: A logical clock is a mechanism used in distributed systems to order events that occur across different nodes in the system. Unlike physical clocks, which are based on real-time measurements of time, logical clocks are not tied to any real-world time reference. Instead, they provide a logical ordering of events based on causality relationships between them.
In distributed systems, there is no global clock exists rather it uses logical clocks to synchronize the events in the system. Logical Clocks refer to implementing a protocol on all machines within distributed system, so that the machines are able to maintain consistent ordering of events within some virtual time span. Logical clocks provide a way to maintain the consistent ordering of events in a distributed system.
A logical clock is a mechanism for capturing chronological and causal relationships in a distributed system. Distributed systems may have no physically synchronous global clock, so a logical clock allows global ordering on events from different processes in such systems.
Logical clocks do not need exact time. So, absolute time is not a concern in logical clocks. Logical clocks just bothers about the message to be delivered or not about the timings of the events occurred.
How logical clock is used to timestamp events?
Logical clocks are used in distributed systems to timestamp events and establish event ordering without relying on synchronized physical clocks. Logical clocks help address the challenges that arise in distributed systems when the absolute ordering of events cannot be determined accurately using physical clocks, due to issues like clock drifts and network latencies.
The most common implementation of logical clocks is the Lamport timestamp, introduced by Leslie Lamport. Each Lamport timestamp is a pair (timestamp, node identifier), where the timestamp represents a logical time value and the node identifier uniquely identifies the node generating the timestamp.
Here’s how a logical clock works and how it is used to timestamp events:
Event Ordering:
- Every time an event occurs at a node in the distributed system, the node increments its logical clock value by one to assign a Lamport timestamp to the event.
- If an event A happens before another event B, the Lamport timestamp of A will be less than the Lamport timestamp of B.
Message Exchange:
- When a node sends a message to another node, it includes its current Lamport timestamp in the message.
- Upon receiving the message, the receiving node updates its own logical clock value to be greater than the maximum of its current logical clock value and the timestamp received in the message. This ensures that the receiving node’s logical clock moves forward to reflect the causality of the received message.
Event Ordering Guarantee:
- The logical clock mechanism guarantees that if event A causally precedes event B, then the Lamport timestamp of event A will be less than the Lamport timestamp of event B.
- However, if events are concurrent (neither causally precedes the other), their Lamport timestamps may not reflect the real-time order of occurrence.
Shortcoming of logical clock:
Logical clocks, while instrumental in ensuring a partial ordering of events in distributed systems, have several limitations. Here are some of the shortcomings of logical clocks:
Only Partial Ordering: Logical clocks, especially Lamport timestamps, only provide a partial order of events. That means that if event A’s timestamp is less than event B’s timestamp, A happened before B. But if A and B have the same timestamp, it doesn’t mean they happened at the same time; it only means their ordering is indeterminate. It’s not necessarily reflective of the real-time order in which events took place.
Overestimation of Causality: Logical clocks can sometimes overestimate causality. For instance, two events from different processes might be assigned timestamps that indicate one happened before the other, even if they’re genuinely concurrent and unrelated.
No Global Total Order: Logical clocks don’t provide a total order of all events in the system. In many applications, it’s beneficial to know the total order of all events across all processes.
Lack of Real-time Information: Logical clocks don’t reflect real-time. For some applications, understanding the actual physical time when an event occurred is crucial, and logical clocks don’t offer this information.
Complexity in Handling Failures: In distributed systems where node failures are common, handling and updating vector clocks can become complex.
Maintenance Overhead: For every event or message exchange, logical clocks (especially vector clocks) need updates. This frequent updating can introduce computational and communication overheads.
(b) What are the different matrices used to measure the performance of a mutual exclusion algorithm? (5)
Ans: Several matrices are commonly used to measure the performance of mutual exclusion algorithms. These matrices help assess the effectiveness, efficiency, and suitability of mutual exclusion algorithms for specific applications and system environments.
Here are some of the matrices used to measure the performance of mutual exclusion algorithms:
Concurrency: This measures how many processes can access the critical section concurrently. Higher concurrency indicates better utilization of resources.
Throughput: Throughput measures the rate at which processes can enter and exit the critical section. Higher throughput indicates better performance, as more processes can execute their critical sections within a given time frame.
Fairness: Fairness evaluates how evenly processes are granted access to the critical section. A fair mutual exclusion algorithm ensures that processes are not unfairly starved or delayed from accessing the critical section.
Starvation and Deadlock: These matrices evaluate whether the mutual exclusion algorithm is prone to starvation (where some processes are indefinitely delayed from accessing the critical section) or deadlock (where processes are blocked indefinitely, waiting for each other).
Scalability: Scalability measures how well the mutual exclusion algorithm performs as the number of processes or resources in the system increases. A scalable algorithm should maintain performance even with larger system sizes.
Fault Tolerance: Fault tolerance evaluates how well the mutual exclusion algorithm handles failures or errors, such as process crashes or network interruptions. A fault-tolerant algorithm should continue to ensure mutual exclusion even in the presence of failures.
(c) What is vector clock? How it overcomes the limitations of Lamport clock? (2+2=4)
Ans: A vector clock is a mechanism used in distributed computing and distributed systems to track the partial ordering of events or operations occurring across multiple processes or nodes. Vector clocks help maintain causality information, allowing processes to determine the relative ordering of events and to detect causal relationships.
Like Lamport’s Clock, Vector Clock is also a logical clock, which is used to assign timestamps for events in a distributed system. Vector clock also gives a partial ordering of the events.
Vector clocks are particularly useful for detecting causality relationships among events in distributed systems. They provide more detailed information than simple Lamport timestamps, as they can differentiate between concurrent events and events with causal relationships.
Here’s how vector clocks address the shortcomings of Lamport clocks:
Vector clocks overcome some of the limitations of Lamport clocks by providing more detailed information about the causal relationships between events in a distributed system. Vector clocks provide a more refined mechanism for capturing causality relationships in distributed systems compared to Lamport clocks, thereby overcoming some of their limitations, particularly regarding the handling of concurrent events and providing more accurate causality information.
Handling of Concurrent Events:
- Lamport Clocks: Lamport timestamps can’t distinguish between truly concurrent events (events that have no causal relationship). If two events have the same Lamport timestamp, it only means that their order is undetermined, but they could still be concurrent.
- Vector Clocks: Vector clocks can accurately resolve the ordering of concurrent events. Vector clocks can distinguish between concurrent events. When two processes perform concurrent events, their vector clock entries remain distinct. The vector clock of one process will have a different value for the corresponding process than the other, indicating that these events are concurrent.
Causality Tracking:
- Lamport Clocks: Lamport timestamps provide a partial ordering of events based on the “happened before” relationship, but they do not capture the causal dependencies between events explicitly.
- Vector Clocks: Vector clocks explicitly capture causality information. When a process updates its vector clock upon message receipt, it takes into account not only its own events but also the events from other processes that it has received messages from. This allows processes to precisely determine causal relationships among events by comparing vector clocks. If vector clock A is less than vector clock B, it indicates that event A causally precedes event B.
Ordering of Concurrent Events:
- Lamport Clocks: Lamport timestamps do not specify any ordering among concurrent events with the same timestamp.
- Vector Clocks: Vector clocks provide a mechanism to order concurrent events based on the relative values of their vector clocks. This can be valuable when it’s essential to establish some level of ordering among concurrent operations.
Scalability and Flexibility:
- Lamport Clocks: In a system with many processes, tracking Lamport timestamps for all processes can be cumbersome, as it requires a separate counter for each process.
- Vector Clocks: Vector clocks are more scalable because they maintain a vector with entries for each process. This structure is adaptable to different numbers of processes without requiring major modifications to the algorithm.
4. (a) What is distribution transparency? What are the different types of distribution transparency? (2+5=7)
Ans: An important goal of a distributed system is to hide the fact that its processes and resources are physically distributed across multiple computers. A distributed system that is able to present itself to users and applications as if it were only a single computer system is said to be transparent. Transparency “is the concealment from the user of the separation of components of a distributed system so that the system is perceived as a whole”.
Types of Transparency:
Access transparency: Access transparency deals with hiding differences in data representation and the way that resources can be accessed by users. At a basic level, we wish to hide differences in machine architectures, but more important is that we reach agreement on how data is to be represented by different machines and operating systems.
Location transparency: Location transparency refers to the fact that users cannot tell where a resource is physically located in the system. Naming plays an important role in achieving location transparency. In particular, location transparency can be achieved by assigning only logical names to resources, that is, names in which the location of a resource is not secretly encoded.
Migration transparency: Distributed systems in which resources can be moved without affecting how those resources can be accessed are said to provide migration transparency.
Relocation transparency: Even stronger is the situation in which resources can be relocated while they are being accessed without the user or application noticing anything. In such cases, the system is said to support relocation transparency.
Replication transparency: replication plays a very important role in distributed systems. For example, resources may be replicated to increase availability or to improve performance by placing a copy close to the place where it is accessed. Replication transparency deals with hiding the fact that several copies of a resource exist. To hide replication from users, it is necessary that all replicas have the same name. Consequently, a system that supports replication transparency should generally support location transparency as well, because it would otherwise be impossible to refer to replicas at different locations.
Concurrency transparency: an important goal of distributed systems is to allow sharing of resources. In many cases, sharing resources is done in a cooperative way, as in the case of communication. However, there are also many examples of competitive sharing of resources. For example, two independent users may each have stored their files on the same file server or may be accessing the same tables in a shared database. In such cases, it is important that each user does not notice that the other is making use of the same resource. This phenomenon is called concurrency transparency.
Failure transparency: Making a distributed system failure transparent means that a user does not notice that a resource (he has possibly never heard of) fails to work properly, and that the system subsequently recovers from that failure.
(b) What is clock synchronization? Why it is required? Differentiate between internal and external synchronization. (3+2+3=8)
Ans: Clock synchronization refers to the process of ensuring that clocks across a distributed system are all adjusted to reflect the same time or are kept closely aligned with each other. Clock synchronization is the mechanism to synchronize the time of all the computers in the distributed environments or system. Assume that there are three systems present in a distributed environment. To maintain the data i.e. to send, receive and manage the data between the systems with the same time in synchronized manner we need a clock that has to be synchronized. This process to synchronize data is known as Clock Synchronization.
Clock synchronization can be achieved using various techniques and protocols, including:
Network Time Protocol (NTP): NTP is a widely used protocol for synchronizing clocks over a network. It relies on a hierarchical structure of time servers, with each level of servers providing increasingly accurate time references. NTP adjusts the local clock rate to gradually align with the reference time.
Precision Time Protocol (PTP): PTP is a more accurate clock synchronization protocol designed for high-precision applications, such as industrial automation and telecommunications. It achieves sub-microsecond synchronization accuracy by using hardware timestamps and precise synchronization messages.
GPS and GNSS: Global Positioning System (GPS) and other Global Navigation Satellite Systems (GNSS) provide highly accurate time references based on atomic clocks onboard satellites. GPS receivers can synchronize local clocks with GPS time to achieve precise timekeeping.
Radio Time Signals: Some regions broadcast time signals over radio frequencies, such as WWV in the United States and DCF77 in Europe. Radio time signals can be used to synchronize local clocks with a reference time source.
Requirement of Clock Synchronization:
Clock synchronization is required in distributed systems because it ensures that all the clocks in the system are in agreement about the current time. clock synchronization is crucial for the proper functioning and reliability of distributed systems, ensuring consistent and accurate timekeeping across all nodes in the system. In a distributed system, where multiple computers or devices interact and collaborate, having synchronized clocks is essential for various reasons, including:
Coordination: Synchronized clocks facilitate coordination and scheduling of tasks and events across distributed nodes. It enables nodes to agree on the order of events, timeouts, and deadlines. Distributed systems often involve multiple nodes working together to perform a task. Coordinating the actions of these nodes requires that they all have a common understanding of the current time.
Data Consistency: In distributed databases and file systems, synchronized clocks help maintain consistency by ensuring that timestamps accurately reflect the ordering of operations or transactions.
Diagnostics: Distributed systems can be complex and difficult to diagnose when something goes wrong. Being able to correlate events across different nodes is much easier if all the clocks are in agreement.
Security: Timestamps are often used in security protocols for authentication, authorization, and auditing purposes. Synchronized clocks help ensure the accuracy and integrity of timestamps used in security mechanisms. Some security protocols rely on timestamps to determine the validity of a message or transaction. If the clocks on different nodes are not in agreement, it can be difficult to determine whether a message is legitimate or not.
Differentiate between internal and external synchronization:
Internal synchronization synchronizes the clocks in the distributed system with one another. The goal of internal synchronization is to keep the readings of a system of autonomous clocks closely synchronized with one another, despite the failure or malfunction of one or more clocks. These clock readings may not have any connection with UTC or GPS time—mutual consistency is the primary goal.
External Synchronization synchronizes each clock in the distributed system with a UTC. The goal of external synchronization is to maintain the reading of each clock as close to the UTC as possible. The primary goal of external synchronization is indeed to maintain the readings of each clock in the distributed system as close to the reference time (e.g., UTC) as possible. By synchronizing all clocks to a common time reference, external synchronization helps ensure consistency, coordination, and accuracy across distributed nodes in the system.
The NTP (Network Time Protocol) is an external synchronization protocol that runs on the Internet and coordinates a number of time servers. This enables a large number of computers connected to the Internet to synchronize their local clocks to within a few milliseconds from the UTC. NTP takes appropriate recovery measures against possible failures of one or more servers as well as the failure of links connecting the servers.
5(a) Explain Huang’s termination detection algorithm with an example. (8)
Ans: Huang’s termination detection algorithm is a distributed algorithm used to detect the termination of a distributed computation or task across multiple processes or nodes in a distributed system. The algorithm was proposed by Shing-Tsaan Huang in 1989 in the Journal of Computers. Huang’s termination detection algorithm ensures that all processes eventually agree on the termination of the distributed computation, even in the presence of message delays or failures in the distributed system.
Huang’s termination detection algorithm is a distributed algorithm used to detect when all processes in a distributed system have completed their tasks, i.e., when the system has terminated. It is a fundamental mechanism for coordinating distributed computations and ensuring that no processes are still active before the system can proceed to the next phase or terminate itself. The algorithm is based on the principle of process counting, where each process informs others about its status.
Assumptions of the algorithm:
- One of the co-operating processes which monitor the computation is called the controlling agent.
- The initial weight of controlling agent is 1.
- All other processes are initially idle and have weight 0.
- The computation starts when the controlling agent sends a computation message to one of the processes.
- The process becomes active on receiving a computation message.
- Computation message can be sent only by controlling agent or an active process.
- Control message is sent to controlling agent by an active process when they are becoming idle.
- The algorithm assigns a weight W (such that 0 < W < 1) to every active process and every in transit message.
Notations used in the algorithm:
- B(DW) – Computation message with weight DW
- C(DW) – Control message with weight DW
Algorithm:
The algorithm is defined by the following four rules:
Rule 1: The controlling agent or an active process, P may send a computation message to one of the processes, say Q, by splitting its weight W into W1 and W2 such that W=W1+W2, W1>0 and W2>0. It then assigns its weight W:=W1 and sends a computation message B(DW:=W2) to Q.
Rule 2: On the receipt of the message B(DW), process Q adds DW to its weight W (W:=W+DW). If the receiving process is in the idle state, it becomes active.
Rule 3: A process switches from the active state to the idle state at any time by sending a control message C(DW:=W) to the controlling agent and making its weight W:=0.
Rule 4: On the receipt of a message C(DW), the controlling agent adds DW to its weight (W:=W+DW). If W=1, then it concludes that the computation has terminated.
Example:
Let’s illustrate the algorithm with an example involving three processes: A, B, and C. Initially, all three processes are in the active state.
Initialization:
Process A, B, and C are active.
No termination messages have been sent.
- Process A Completes:
- Process A finishes its work and sends “termination” messages to B and C.
- Process A marks itself as terminated.
- Process B Receives A’s Termination Message:
- Process B receives A’s “termination” message and acknowledges it.
- Process B checks its own termination status, as well as the status of the processes it knows about (A and C). Since it hasn’t received termination messages from C yet, it remains active.
- Process C Receives A’s Termination Message:
- Process C receives A’s “termination” message and acknowledges it.
- Process C checks its own termination status and the status of the processes it knows about (A and B). Since it hasn’t received termination messages from B yet, it remains active.
- Process B Completes:
- Process B finishes its work and sends “termination” messages to A and C.
- Process B marks itself as terminated.
- Process C Receives B’s Termination Message:
- Process C receives B’s “termination” message and acknowledges it.
- Process C now checks its own termination status and the status of the processes it knows about (A and B). Since it has received termination messages from both A and B, it marks itself as terminated.
- Final State:
- All processes (A, B, and C) have marked themselves as terminated because they’ve received termination messages from all other processes they know about.
- The system has detected termination, and it can now proceed to the next phase of computation or shut down gracefully.
Huang’s termination detection algorithm ensures that all processes communicate their termination status to others and collectively agree on when the entire distributed system has completed its tasks. This is vital for maintaining the correctness and coordination of distributed applications.
(b) What is an election algorithm? What are the requirements of an election algorithm? Explain Bully algorithm with an example. 3+4=7
Ans: An election algorithm is a distributed algorithm used to elect a single process or node as a leader or coordinator among a group of processes or nodes in a distributed system. The leader role is often important for coordinating activities, making decisions, or providing centralized control in the distributed system.
Election algorithm chooses a process from a group of processes to act as a coordinator. If the coordinator process crashes due to some reasons, then a new coordinator is elected from other processes. Many distributed algorithms require one process to act as coordinator, initiator, or otherwise perform some special role. The coordinator process plays an important role in the distributed system to maintain the consistency through synchronization.
Synchronization between processes often requires that one process acts as a coordinator. In those cases where the coordinator is not fixed, it is necessary that processes in a distributed computation decide on who is going to be that coordinator. Such a decision is taken by means of Election Algorithms. Election algorithms are primarily used in cases where the coordinator can crash. However, they can also be applied for the selection of superpeers in peer-to-peer systems.
Requirement of Election Algorithm:
Many distributed algorithms require one process to act as coordinator, initiator, or otherwise perform some special role. The coordinator process plays an important role in the distributed system to maintain the consistency through synchronization.
The need for an election algorithm in distributed systems arises from several key requirements and challenges inherent in such systems:
Fault Tolerance: Distributed systems often consist of multiple nodes that can fail independently due to hardware failures, software errors, or network partitions. To maintain system functionality in the presence of failures, it’s crucial to have a mechanism for dynamically electing new leaders or coordinators to take over the responsibilities of failed nodes.
Coordination: Many distributed systems require a single node to act as a coordinator or leader to coordinate the activities of other nodes, such as in distributed databases, consensus protocols, or cluster computing. An election algorithm ensures that a new coordinator can be quickly and efficiently elected when needed.
Scalability: As distributed systems grow in size, the overhead of centralized coordination or manual intervention becomes prohibitive. An election algorithm enables the automatic selection of leaders without requiring explicit configuration or management, thus supporting scalability.
Dynamic Membership: Distributed systems often have dynamic membership, where nodes can join or leave the system at any time. An election algorithm allows the system to adapt to changes in membership by electing new leaders as needed, ensuring continuity of operations.
Bully Algorithm:
The Bully Algorithm is a type of Election Algorithm. This algorithm was proposed by Garcia-Molina (1982). The idea behind the Bully Algorithm is to elect the highest-numbered process as the coordinator.
When any process notices that the coordinator is not active, crashed or no longer responding to requests, it initiates an election. A process, P, holds an election as follows:
- P sends an ELECTION message to all processes with higher numbers.
- If no one responds, P wins the election and becomes coordinator.
- If one of the higher-ups answers, it takes over. P’s job is done or finish.
At any moment, a process can receive an ELECTION message from any one of its lower-numbered process. When such a message arrives, the receiver sends an OK message back to the sender to indicate that it is active and will take over. The receiver then holds an election, unless it is already holding one. Eventually, all processes give up but one, and that one is the new coordinator. It announces its victory by sending all processes a message telling them that starting immediately it is the new coordinator.
If a process that was previously down comes back up, it holds an election. If it happens to be the highest-numbered process currently running, it will win the election and take over the coordinator’s job. Thus the biggest guy in town always wins, hence the name “bully algorithm.”
Figure below shows an example of how the Bully Algorithm works.

Fig-1
The group consists of eight processes, numbered from 0 to 7. Previously process 7 was the coordinator, but it has just crashed. Process 4 is the first one to notice this, so it sends ELECTION messages to all the processes higher than it, namely 5, 6, and 7 as shown in Fig-1.
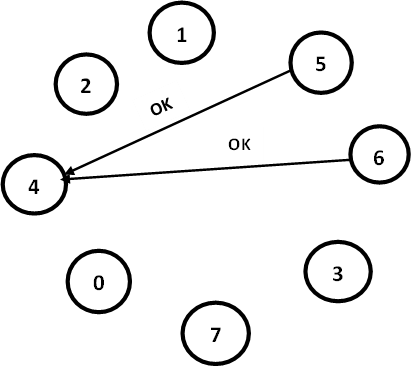
Fig-2
Processes 5 and 6 both respond with OK, as shown in Fig-2. Upon getting the responses, process 4 job is over. It knows that one of these will take over and become coordinator. It just sits back and waits to see who the winner will be.

Fig-3
In Fig-3, both 5 and 6 hold elections, each one sending ELECTION messages to those processes higher than itself.

Fig-4
In Fig-4 process 6 tells 5 that it will take over with an OK message. At this point 6 knows that 7 is dead and that it (6) is the winner. If there is state information to be collected from disk or elsewhere to pick up where the old coordinator left off, 6 must now do what is needed. When it is ready to take over, 6 announces this by sending a COORDINATOR message to all running processes shown in fig-5.

Fig-5
When 4 gets this message, it can now continue with the operation it was trying to do when it discovered that 7 was dead, but using 6 as the coordinator this time. In this way the failure of 7 is handled and the work can continue.
If process 7 is ever restarted, it will just send all the others a COORDINATOR message and bully them into submission.
6 (a) What is distributed mutual exclusion? What are the requirements of distributed mutual exclusion ? Explain Maekawa’s voting algorithm for mutual exclusion. Show how it satisfies the requirement of mutual exclusion.(2+3+5=10)
Ans: Distributed processes often need to coordinate their activities. If a collection of processes share a resource or collection of resources, then often mutual exclusion is required to prevent interference and ensure consistency when accessing the resources. Mutual exclusion ensures that at a time only one of the concurrent processes are allowed to access the common or shared resources. In case of distributed systems, where multiple sites are considered it is named as distributed mutual exclusion (DME).
Mutual exclusion is a fundamental problem in distributed computing systems. Mutual exclusion ensures that concurrent access of processes to a shared resource or data is serialized, that is, executed in a mutually exclusive manner. Mutual exclusion in a distributed system states that only one process is allowed to execute the critical section (CS) at any given time. In a distributed system, shared variables (semaphores) or a local kernel cannot be used to implement mutual exclusion. Distributed mutual exclusion is based on message passing.
Requirements of Mutual Exclusion:
Essential requirements for mutual exclusion are as follows:
ME1: safety: The foremost requirement of mutual exclusion is safety, meaning that at most one process can execute in the critical section (CS) at a time. No two process must be allowed entering in critical section at same time. This ensures that conflicting operations do not occur simultaneously, preventing data corruption or integrity issues.
ME2: liveness: While ensuring safety, mutual exclusion algorithms should also guarantee liveness, meaning that processes are eventually allowed to enter the critical section if they request access. This ensures progress in the system and prevents deadlock scenarios where processes are indefinitely blocked from entering the critical section. Mutual exclusion should be free from deadlocks. Process entering into critical section should release it in a finite time so, that a fair chance is given to all other process.
ME3: Ordering: Access is granted in the happened before relation. If one request to enter the CS happened-before another, then entry to the CS is granted in that order. If request A happens-before request B then grant A before grant B.
Maekow’s Voting Algorithm:
Maekawa’s Algorithm is an algorithm for achieving mutual exclusion in a distributed system. It is a deadlock free algorithm that ensures that only one process can enter the critical section at any given time. The algorithm allows multiple processes to access a shared resource without interfering with each other. It is based on the concept of quorum. Maekawa’s Algorithm is actually considered a quorum-based algorithm, rather than a pure voting-based algorithm. It utilizes a voting mechanism within each quorum to determine access to the critical section.
In Maekawa’s Algorithm, processes are organized into a set of disjoint quorums. Each process can grant permission to enter the critical section to other processes within its quorum. A process can enter the critical section only when it has received permission from all processes in its quorum. This algorithm utilizes a voting mechanism within the quorums to determine access to the critical section.
Maekawa’s Algorithm ensures mutual exclusion by guaranteeing that only one process from each quorum can access the critical section simultaneously. This allows for efficient utilization of resources while preventing race conditions and conflicts.
A quorum is defined as a set of processes that satisfies two conditions:
- Any two quorums have at least one process in common.
- The intersection of all quorums is non-empty.
Here’s a brief overview of Maekawa’s Algorithm:
Partitioning into Quorums: The system’s processes are divided into several disjoint subsets or quorums. Each quorum consists of a subset of processes.
Voting within Quorums: When a process wants to enter the critical section, it sends a request to all processes within its quorum.
Quorum Voting: Each process in the quorum votes on whether the requesting process can enter the critical section based on certain criteria. Typically, the criteria involve ensuring that only one process at a time from each quorum enters the critical section.
Granting Access: If the requesting process receives enough affirmative votes from its quorum, it can enter the critical section.
Releasing Access: Once a process completes its critical section execution, it releases access, allowing another process to enter.
The algorithm works as follows:
- Each process maintains a list of its own quorums and the quorums of other processes.
- When a process wants to access the shared resource, it sends a request message to all the processes in its quorum.
- If a process receives a request message, it checks if it is currently accessing the shared resource. If it is not, it adds the requesting process to its own quorum and sends a reply message.
- If a process receives a reply message from all the processes in its own quorum, it grants the request to access the shared resource.
- Once the process has finished accessing the shared resource, it sends a release message to all the processes in its quorum, and they remove it from their quorums.
Maekawa’s voting algorithm is a distributed mutual exclusion algorithm that satisfies the requirement of mutual exclusion by allowing processes in a distributed system to request access to a shared resource in a coordinated manner while ensuring that only one process at a time can enter the critical section.
(b) What is happened before relationship? What are its different rules? (5)
Ans : The “happened-before” relation is a concept used in distributed systems to define a partial ordering of events based on their causality. It helps establish the order of events in a distributed system even when events occur concurrently across different processes or components. The happened-before relation is a fundamental concept in logical clock algorithms such as Lamport clocks and vector clocks. The happened-before relation establishes a partial ordering of events in a distributed system. It does not necessarily provide a total ordering of events but instead defines a set of rules for comparing the ordering of events based on their causality.
In distributed system, the happened-before relation (denoted: ->) is a relation between the result of two events, such that if one event should happen before another event, the result must reflect that, even if those events are in reality executed out of order (usually to optimize program flow). This involves ordering events based on the potential causal relationship of pairs of events in a concurrent system, specially asynchronous distributed systems. It was formulated by Leslie Lamport.
The happened-before relation is formally defined as the least strict partial order on events such that:
- If a and b are events in the same process, and a occurs before b, then a ->b is true.
- If a is the event of a message being sent by one process, and b is the event of the message being received by another process, then a -> b is also true. A message cannot be received before it is sent, or even at the same time it is sent, since it takes a finite, nonzero amount of time to arrive.
If two events happen in different isolated processes (that do not exchange messages directly or indirectly via third-party processes), then the two processes are said to be concurrent, that is neither a->b nor b->a is true.
Rules for Establishing Happened-Before:
Within the Same Process: If event A occurs before event B within the same process, then A happened-before B. This is straightforward and reflects the natural temporal order of events within a process.
Message Ordering: If event A is the sending of a message and event B is the receipt of the same message, then A happened-before B. This rule ensures that message receipt events occur after their corresponding message sending events.
Transitivity: If event A happened-before event B, and event B happened-before event C, then event A also happened-before event C. This rule ensures the consistency of the happened-before relation across multiple events.
Happens-before is a transitive relation, so if a->b and b -> c, then a -> c. If two events, x and y, happen in different processes that do not exchange messages (not even indirectly via third parties), then x->y is not true, but neither is y -> x. These events are said to be concurrent, which simply means that nothing can be said (or need be said) about when the events happened or which event happened first.

The happened-before relation, denoted by -> is illustrated for the case of three processes p1, p2 and p3 in figure above. It can be seen that a->b, since the events occur in this order at process p1 and similarly c->d. Furthermore, b->c, since these events are the sending and reception of message m1, and similarly d->f. Combining these relations, we may also say that, for example, a->f.
7 (a) What is distributed transaction? Differentiate between flat and nested transaction. (2+3=5)
Ans: A distributed transaction in a distributed system refers to a transaction that spans multiple nodes or components within the system. In other words, it involves multiple processes or databases that are geographically distributed across a network. Distributed transactions are used to ensure data consistency and integrity when multiple resources need to be updated or modified as part of a single, logically cohesive operation.
Distributed transactions involve more than one server. A distributed transaction is any transaction whose activity involves several different servers. A client transaction becomes distributed if it invokes operations in several different servers.
Here are some key characteristics and concepts related to distributed transactions:
Atomicity: Just like in traditional single-node transactions, the concept of atomicity applies to distributed transactions as well. Atomicity ensures that either all the changes made by a distributed transaction are applied successfully (commit) or none of them are applied (rollback). This guarantees that the system remains in a consistent state.
Consistency: Distributed transactions ensure data consistency across all participating nodes or databases. This means that the data remains valid and adheres to the defined constraints and rules, even after a distributed transaction is completed.
Isolation: Isolation in distributed transactions refers to the degree to which one transaction is isolated from the effects of other concurrent transactions.
Durability: Durability guarantees that once a distributed transaction is committed, its changes are permanently stored and will survive system failures.
Flat and Nested Distributed Transaction:
In a distributed system, transactions are used to ensure the consistency and integrity of data when multiple processes or nodes are involved. Two common approaches to handling transactions in a distributed system are flat transactions and nested transactions.
In a flat transaction, a client makes requests to more than one server. A flat client transaction completes each of its requests before going on to the next one. Therefore, each transaction accesses servers’ objects sequentially. When servers use locking, a transaction can only be waiting for one object at a time.
In a nested transaction, the top-level transaction can open sub-transactions, and each sub-transaction can open further sub-transactions down to any depth of nesting.
Differences between Flat and Nested Transaction:
The key difference between flat and nested transactions in distributed systems lies in their structure and the ability to have sub-transactions within a parent transaction. Flat transactions are standalone, single-level transactions, whereas nested transactions allow for hierarchical, multi-level transactions, providing more fine grained control over individual parts of the transaction while still adhering to the atomicity principle.
Here’s a breakdown of the key difference between flat and nested transaction-
Transaction Scope:
- Flat Transactions: In a flat transaction model, each transaction operates independently and does not contain sub-transactions within it. It is simple, single-level transaction structure.
- Nested Transactions: Nested transactions, on the other hand, allow transactions to be nested within one another. This means that a higher-level transaction can contain one or more sub-transactions. These sub-transactions can be committed or rolled back independently, but the final outcome of the top-level transaction depends on the outcomes of its nested transactions.
Atomicity:
- Flat Transactions: Each flat transaction is atomic in itself, meaning it is either fully completed and committed or fully rolled back. There is no concept of nesting or partial commit/rollback within a single transaction.
- Nested Transactions: Nested transactions allow for partial commits and rollbacks within a single top-level transaction. This means that we can commit some changes made by nested transactions while rolling back others within the same top-level transaction.
Coordination:
- Flat Transactions: Flat transactions do not require coordination between multiple transactions. Each transaction operates independently, and there is no need to track dependencies or relationships between them.
- Nested Transactions: Nested transactions require coordination between the top-level transaction and its nested transactions. The outcome of the top-level transaction depends on the success or failure of its nested transactions. This coordination adds complexity but allows for more fine-grained control over transaction outcomes.
(b) What is distributed deadlock? Explain edge chasing algorithm with the help of an example. (2+6=8)
Ans: Deadlock is a fundamental problem in distributed systems. A deadlock is a condition in a system where a process cannot proceed because it needs to obtain a resource held by another process but it itself is holding a resource that the other process needs.
In a distributed system involving multiple servers being accessed by multiple transactions, a global wait-for graph can be constructed from the local ones. There can be a cycle in the global wait-for graph that is not in any single local one – that is, there can be a distributed deadlock.
Distributed deadlocks can occur in distributed systems when distributed transactions or concurrency control are used. It is identified via a distributed approach such as edge chasing or constructing a global wait-for graph (WFG) from local wait-for graphs at a deadlock detector.
Edge Chasing Algorithm:
The edge chasing algorithm is a distributed algorithm used for deadlock detection in distributed systems. A distributed approach to deadlock detection uses a technique called edge chasing or path pushing. In this approach, the global wait-for graph is not constructed, but each of the servers involved has knowledge about some of its edges. The servers attempt to find cycles by forwarding messages called probes, which follow the edges of the graph throughout the distributed system. A probe message consists of transaction wait-for relationships representing a path in the global wait-for graph.
Edge-Chasing Algorithms have three steps– initiation, detection and resolution:
Initiation: When a server notes that a transaction T starts waiting for another transaction U, where U is waiting to access an object at another server, it initiates detection by sending a probe containing the edge <T→U> to the server of the object at which transaction U is blocked. If U is sharing a lock, probes are sent to all the holders of the lock. Sometimes further transactions may start sharing the lock later on, in which case probes can be sent to them too.
Detection: Detection consists of receiving probes and deciding whether a deadlock has occurred and whether to forward the probes.
For example, when a server of an object receives a probe <T→U>(indicating that T is waiting for a transaction U that holds a local object), it checks to see whether U is also waiting. If it is, the transaction it waits for (for example, V) is added to the probe (making it <T→U→V>) and if the new transaction (V) is waiting for another object elsewhere, the probe is forwarded.
In this way, paths through the global wait-for graph are built one edge at a time. Before forwarding a probe, the server checks to see whether the transaction (for example, T) it has just added has caused the probe to contain a cycle (for example, <T→U →V→T>). If this is the case, it has found a cycle in the graph and a deadlock has been detected.
Resolution: When a cycle is detected, a transaction in the cycle is aborted to break the deadlock.
Example to illustrate the edge chasing algorithm:
Consider a distributed system with four processes (P1, P2, P3, P4) and three resources (R1, R2, R3). The resource allocation and request relationships between processes can be represented as follows:
- P1 allocates R1 to P2.
- P2 allocates R2 to P3.
- P3 allocates R3 to P1.
- P4 requests R1 from P1.
In this example, if process P1 initiates deadlock detection using the edge chasing algorithm, it would trace edges in the graph to identify cycles. Tracing the edges, P1→P2→ P3→ P1 forms a cycle, indicating potential deadlock. Process P1 can then report the deadlock to the other processes involved in the cycle, and appropriate actions can be taken to resolve the deadlock situation.
(c) Define what is meant by a scalable system. (2)
Ans: The Scalable System refers to the system in which there is a possibility of extending the system as the number of users and resources grows with time. A scalable system is one that can continue functioning well even as it experiences higher usage. A system is scalable when it has the capacity to accommodate a greater amount of usage.
A scalable system is one that can handle increasing workloads or growing demands while maintaining or improving its performance, capacity, and efficiency. Scalability is the measure of how well that system responds to changes by adding or removing resources to meet demands. Scalability refers to the ability of a system to adapt and expand its resources seamlessly to accommodate changes in workload, data volume, or user traffic without compromising performance, reliability, or user experience.
A scalable system is designed to grow and adapt to changing requirements and usage patterns, allowing organizations to meet the needs of their users or customers effectively and efficiently while maximizing resource utilization and minimizing costs.
Characteristics of a scalable system:
Performance: A scalable system should maintain or improve its performance metrics, such as response time, throughput, and latency, even as the workload or user traffic increases.
Availability: A scalable system should remain available and responsive to user requests, even during peak usage periods or in the face of failures or disruptions.
Reliability: A scalable system should maintain data consistency, integrity, and reliability, ensuring that user data is not lost or corrupted as the system scales.
Manageability: A scalable system should be easy to manage and administer, with tools and mechanisms for monitoring, scaling, and troubleshooting to ensure optimal performance and reliability.